










-
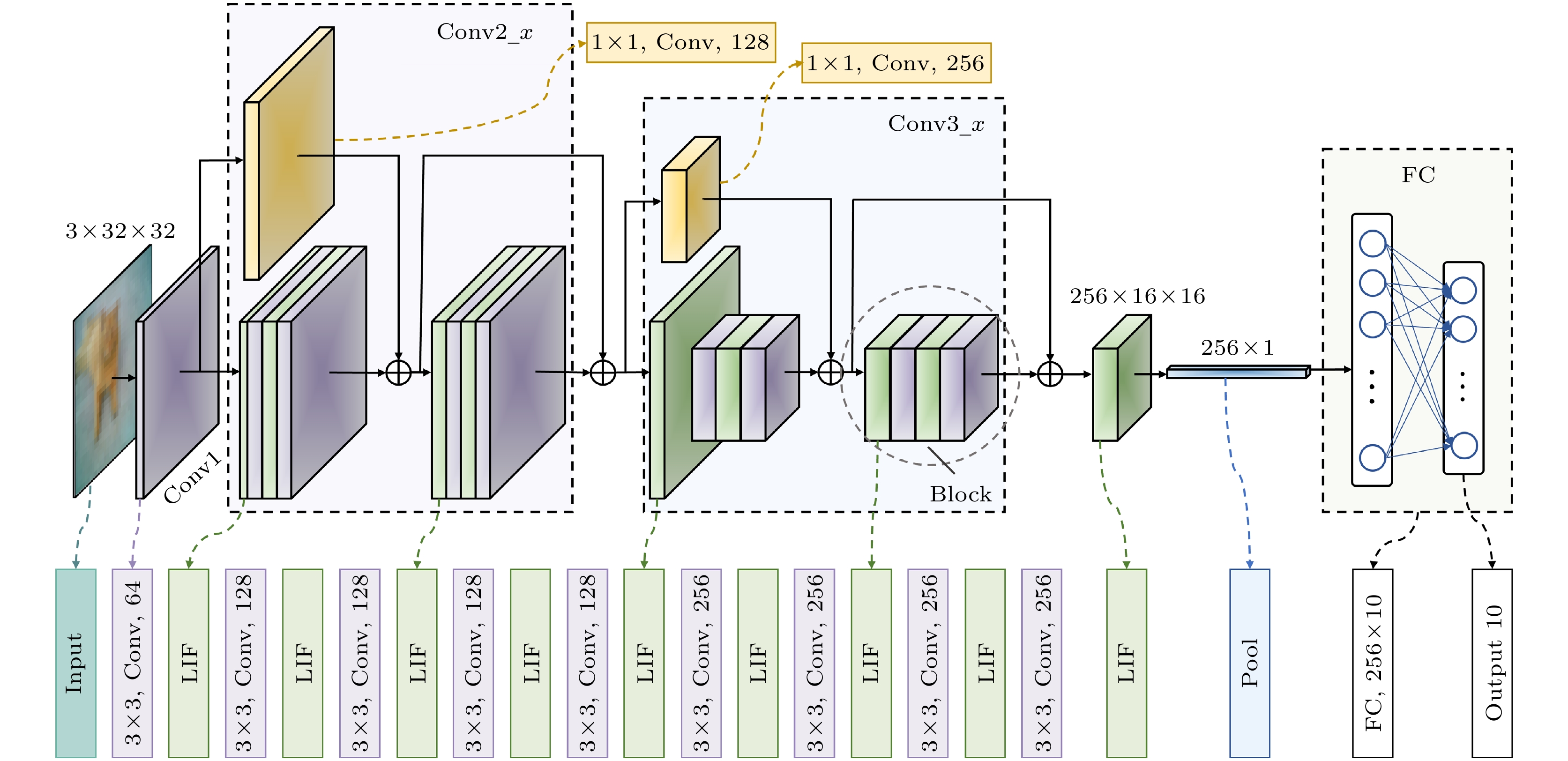
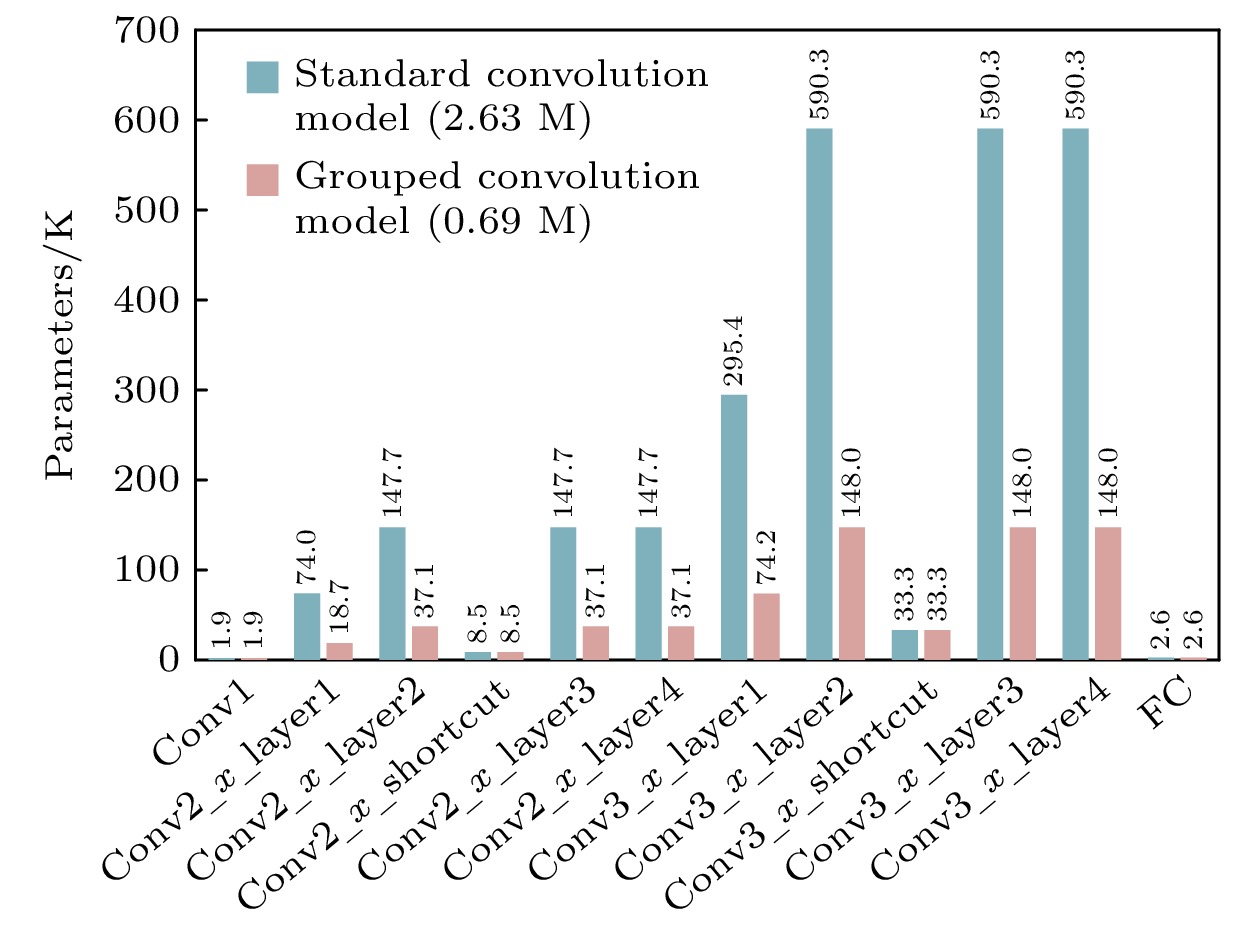
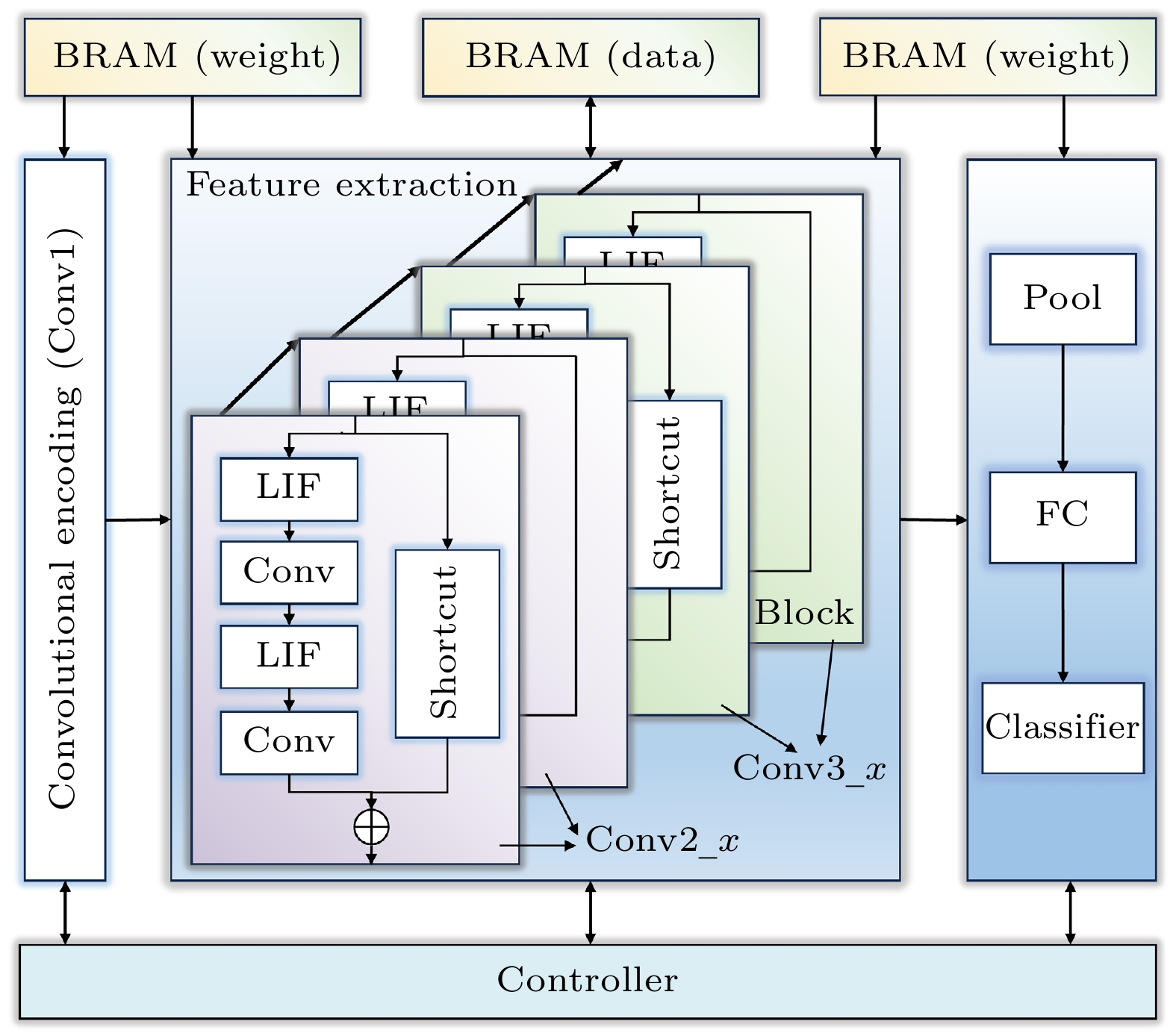
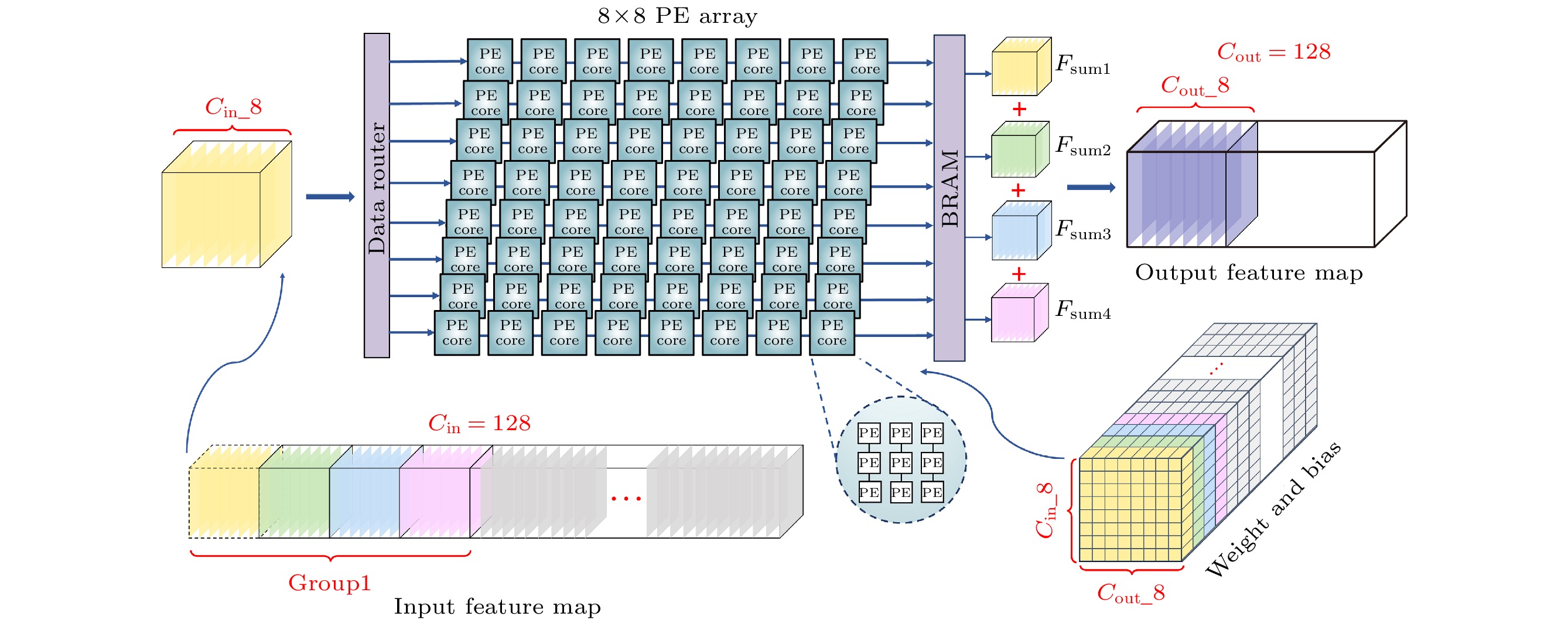
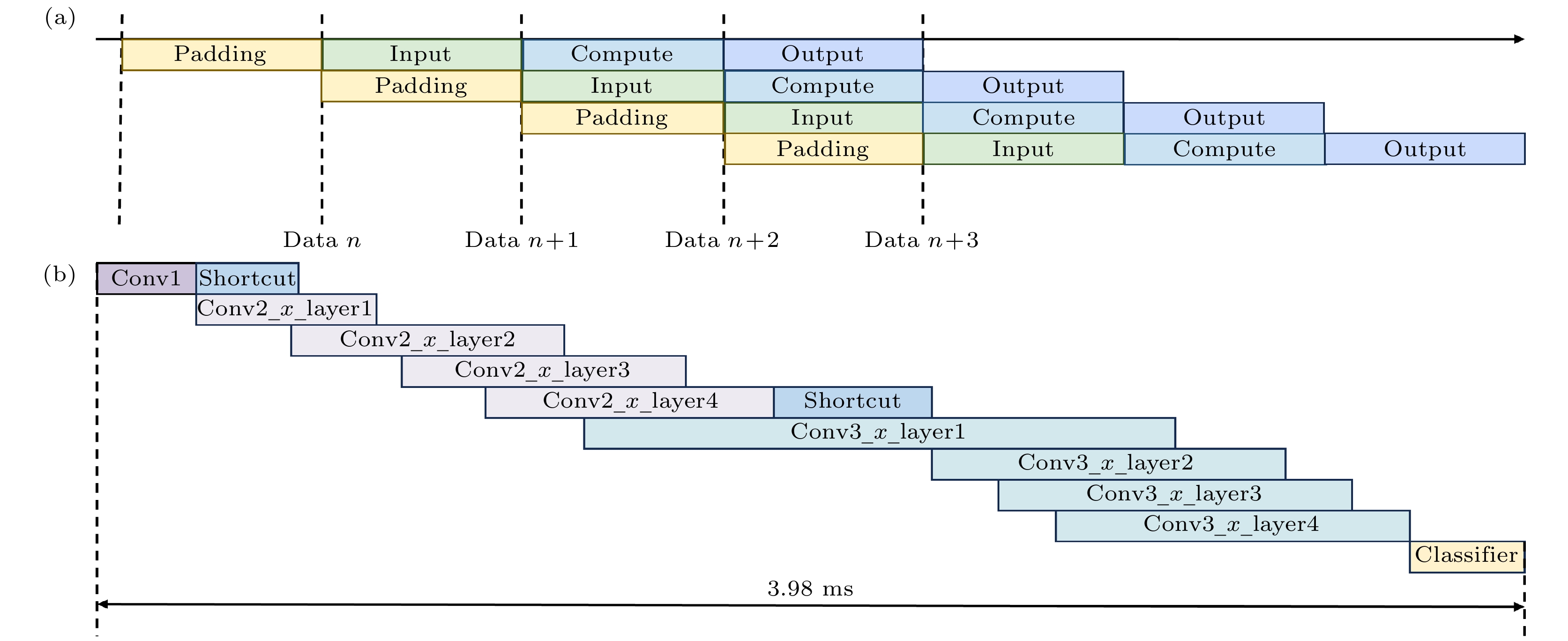
随着脉冲神经网络(spiking neural network, SNN)在硬件部署优化方面的发展, 基于现场可编程门阵列(field-programmable gate array, FPGA)的SNN处理器因其高效性与灵活性成为研究热点. 然而, 现有方法依赖多时间步训练和可重配置计算架构, 增大了计算与存储压力, 降低了部署效率. 本文设计并实现了一种高能效、轻量化的残差SNN硬件加速器, 采用算法与硬件协同设计策略, 以优化SNN推理过程中的能效表现. 在算法上, 采用单时间步训练方法, 并引入分组卷积和批归一化(batch normalization, BN)层融合技术, 有效压缩网络规模至0.69M. 此外, 采用量化感知训练(quantization-aware training, QAT), 将网络参数精度限制为8 bit. 在硬件设计上, 本文通过层内资源复用提高FPGA资源利用率, 采用全流水层间架构提升计算吞吐率, 并利用块随机存取存储器(block random access memory, BRAM)存储网络参数和计算结果, 以提高存储效率. 实验表明, 该处理器在CIFAR-10数据集上分类准确率达到87.11%, 单张图片推理时间为3.98 ms, 能效为183.5 frames/(s·W), 较主流图形处理单元(graphics processing unit, GPU)平台能效提升至2倍以上, 与其他SNN处理器相比, 推理速度至少提升了4倍, 能效至少提升了5倍.With the development of hardware-optimized deployment of spiking neural networks (SNNs), SNN processors based on field-programmable gate arrays (FPGAs) have become a research hotspot due to their efficiency and flexibility. However, existing methods rely on multi-timestep training and reconfigurable computing architectures, which increases computational and memory overhead, thus reducing deployment efficiency. This work presents an efficient and lightweight residual SNN accelerator that combines algorithm and hardware co-design to optimize inference energy efficiency. In terms of algorithm, we employ single-timesteps training, integrate grouped convolutions, and fuse batch normalization (BN) layers, thus compressing the network to only 0.69M parameters. Quantization-aware training (QAT) further constrains all parameters to 8-bit precision. In terms of hardware, the reuse of intra-layer resources maximizes FPGA utilization, a full pipeline cross-layer architecture improves throughput, and on-chip block RAM (BRAM) stores network parameters and intermediate results to improve memory efficiency. The experimental results show that the proposed processor achieves a classification accuracy of 87.11% on the CIFAR-10 dataset, with an inference time of 3.98 ms per image and an energy efficiency of 183.5 FPS/W. Compared with mainstream graphics processing unit (GPU) platforms, it achieves more than double the energy efficiency. Furthermore, compared with other SNN processors, it achieves at least a fourfold increase in inference speed and a fivefold improvement in energy efficiency.
[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] -
名称 消耗资源 可用资源 百分比/% LUTs 134859 425280 31.71 FF 341722 850560 40.18 BRAM 674.5 1080 62.45 DSP 3008 4272 70.41  下载: 导出CSV
下载: 导出CSV
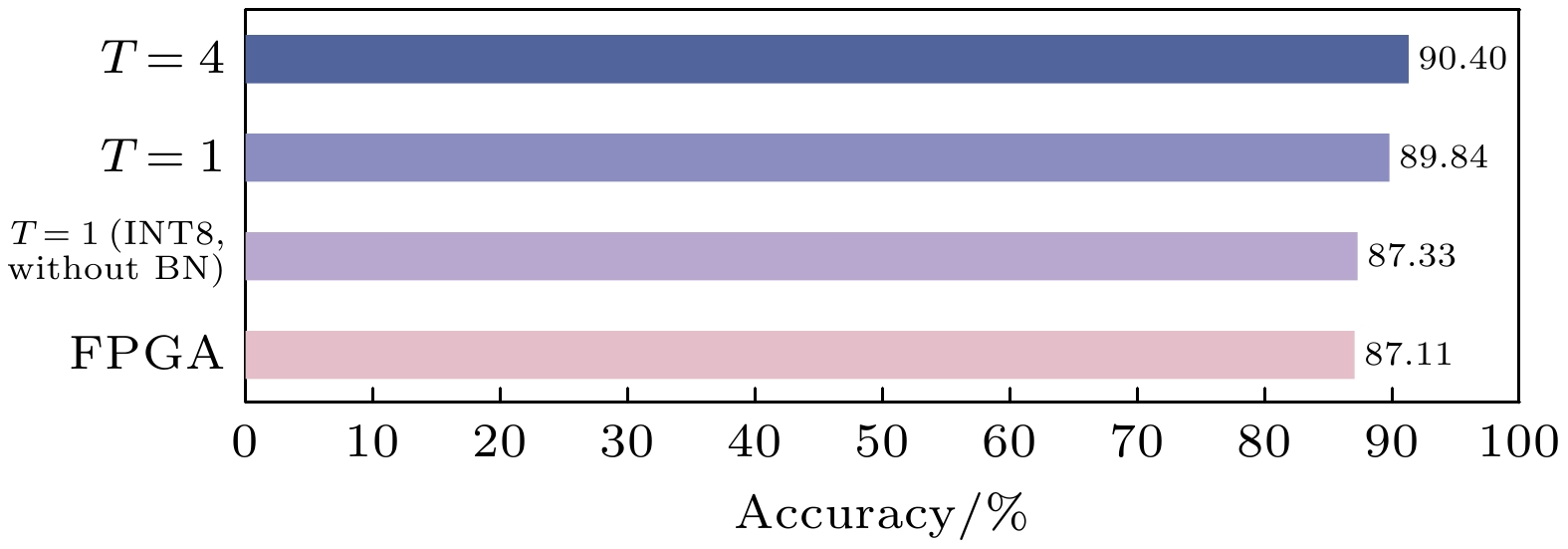
硬件平台 ZCU216 FPGA GeForce RTX 4060 Ti 准确率/% 88.11 88.33 功耗/W 1.369 51 单张图片推理
时间/ms3.98 0.243 FPS 251 4115 FPS/W 183.5 80.7
下载: 导出CSV
平台 E3NE[21] SCPU[22] SiBrain[23] Aliyev et al.[24] 本文 FPGA型号 XCVU13 P Virtex-7 Virtex-7 XCVU13 P ZCU216 频率/MHz 150 200 200 100 100 SNN模型 AlexNet ResNet-11 CONVNet(VGG-11) VGG-9 ResNet-10 模型深度 8 11 6(11) 9 10 精度/bits 6 8 8(8) 4 8 参数量/M — — 0.3(9.2) — 0.69 LUTs/FFs 48k/50k 178k/127k 167k/136k(140k/122k) — 135k/342k 准确率/% 80.6 90.60 82.93(90.25) 86.6 87.11 功率/W 4.7 1.738 1.628(1.555) 0.73 1.369 时延/ms 70 25.4 1.4(18.9) 59 3.98 FPS 14.3 39.43 696(53) 16.95 251 FPS/W 3.0 22.65 438.8(34.1) 23.21 183.5
下载: 导出CSV
-
[1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36]

 下载:
下载:
计量
- 文章访问数: 846
- PDF下载量: 33
- 被引次数: 0